Streamlining Data Extraction with AI
 2 min read
2 min read
Accelerating Document Digitization: How Sarvika Engineered an AI-Powered Data Extraction Solution
A prominent Inc. 5000 EdTech enterprise in the United States—renowned for providing flexible, self-paced virtual education to adult learners, high school students, and homeschoolers—was hit by a massive operational bottleneck due to legacy, manual document handling workflows.
- Traditional transcript evaluation methods failed to scale alongside rapidly increasing student enrollment numbers.
- Despite possessing a cutting-edge frontend learning platform, their backend credit transfer auditing remained slow, highly error-prone, and financially unscalable.
The Challenge: Operational Friction in Manual Document Auditing
- Labor-Intensive Inefficiencies: Human academic auditors had to manually parse and type critical course data (including grades, course names, and credits) from highly fragmented transcript formats, severely capping daily output.
- Elevated Compliance Risks: Fatigue-driven typos and manual inaccuracies frequently caused student credit mismatches, leading to administrative rework and discrepancies in official academic records.
- Infrastructure Scaling Blocks: The rigid, human-dependent workflow could not absorb sudden traffic surges during peak admission cycles, resulting in massive processing backlogs.
- Structural Unpredictability: Transcripts arriving from thousands of independent global institutions lacked any standardized template, rendering basic rule-based software completely useless.
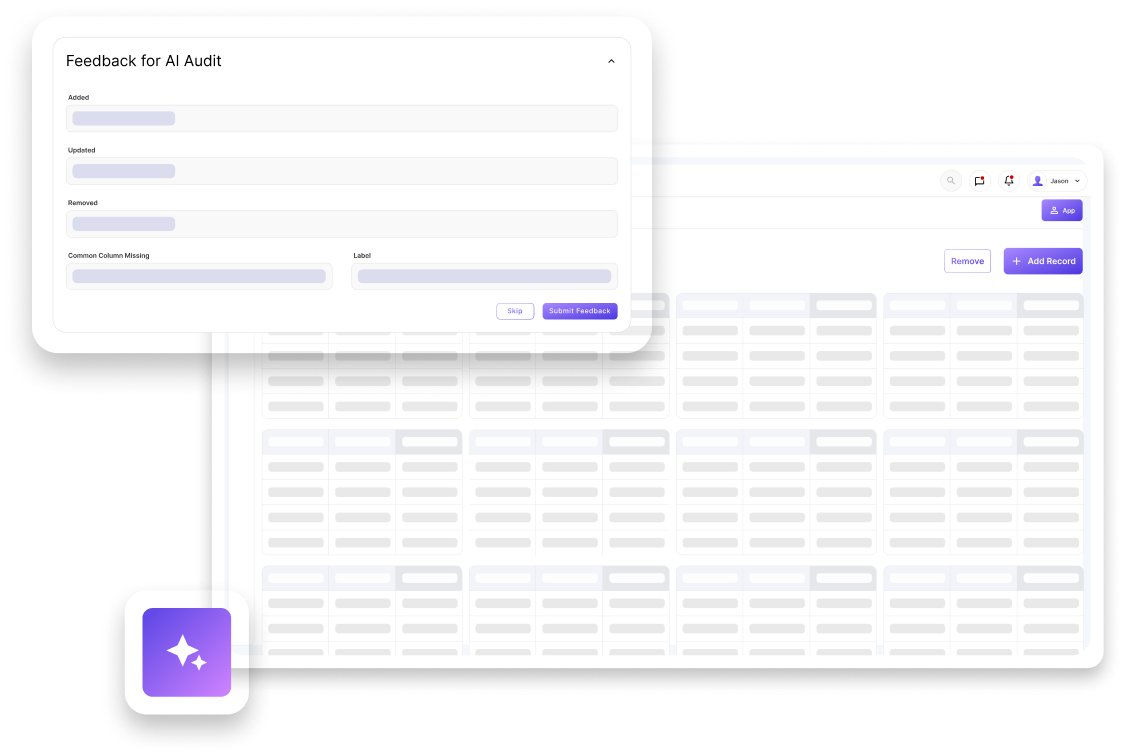
The Solution: Next-Gen Intelligent Document Processing (IDP) Platform
- Cognitive AI Extraction Core: Sarvika developed a custom Automated Transcript Recognition (ATR) engine leveraging state-of-the-art OCR (Optical Character Recognition) coupled with deep learning NLP (Natural Language Processing) to understand structural intent and extract data with high contextual intelligence.
- Human-in-the-Loop (HITL) Dashboard: Designed a unified, interactive validation interface that allows internal data auditors to quickly cross-check, tweak, and approve the AI’s structured outputs.
- High-Throughput Batch Processing: Built robust automated data pipelines capable of ingesting, parsing, and structured-mapping multi-page institutional documents in large bulk volumes instantly.
- Self-Evolving Feedback Architecture: Implemented an active learning loop where human real-time corrections are fed directly back into the underlying machine learning models, dynamically boosting accuracy rates over time.
Business Transformation & Measurable Impact
- 80% Compression in Turnaround Time: Complex academic document auditing and data entry cycles dropped from hours to mere minutes per batch.
- Flawless Data Accuracy (>99%): Eliminated systematic data entry errors, safeguarding compliance metrics and ensuring absolute data integrity across systems.
- Elastic Scale for Admission Spikes: Empowered the client to smoothly process exponentially growing document streams without expanding operational team overheads.
- Strategic Resource Optimization: Shifted internal human capital from exhausting manual data-entry chores to high-impact analytical validation roles.
Performance Benchmarks: Manual Process vs. Intelligent Automation
| Key Performance Indicators (KPIs) | Legacy Manual Process | Optimized AI Engine |
|---|---|---|
| Average Evaluation Time | 30 Minutes / Document | < 5 Minutes / Document |
| Data Entry Error Margin | 12% Average | < 1% (Negligible) |
| Monthly Document Throughput | Up to 500 Records | 3,000+ Scalable Transcripts |
| Structural Layout Adaptation | Highly Restricted | 1,000+ Layouts Supported |
and much more for
![]() Branded Solutions
Branded Solutions
and much more for
![]() Branded Solutions
Branded Solutions
and much more for
![]() Branded Solutions
Branded Solutions
and more for
![]()
Other
Projects